OTTO Dieu-Puissant Cyprien
M2 - Informatique, Parcours Reséaux & Algorithmique Avancée
Sorbonne Université
2024-2025
Recherches personnelles pour des fins académiques. Toutes les sources externes utilisées ont été correctement citées.
Dissertation sur l'algorithme BuiXuan-Hourcade-Miachon pour la détection des jumeaux temporels dans les graphes temporels
Introduction
Dans le cadre de ce projet, nous nous intéressons à une problématique centrale en théorie des graphes et dans l'analyse des réseaux temporels : l'énumération des paires de "jumeaux temporels" dans les graphes dynamiques. Les graphes temporels, qui représentent des interactions ou relations évoluant au fil du temps, sont un outil puissant pour modéliser divers phénomènes tels que les réseaux sociaux, les systèmes de transport, ou encore les communications électroniques. Dans ce contexte, deux sommets peuvent être considérés comme des "jumeaux temporels" s'ils partagent exactement les mêmes voisins (hors d'eux-mêmes) pendant une période donnée. Cette notion, bien qu'apparemment simple, soulève des défis algorithmiques complexes liés à la taille et à la structure des données.
L'approche proposée par Bui-Xuan, Hourcade et Miachon repose sur une technique classique mais essentielle en théorie des graphes : l'affinage de partition. Ce processus permet de regrouper des sommets ayant des propriétés similaires tout en affinant progressivement ces groupes pour identifier des structures plus fines, telles que les modules ou les jumeaux. L'affinage de partition est un outil fondamental dans de nombreux domaines de l'informatique, notamment pour la décomposition modulaire, la reconnaissance de graphes particuliers (comme les cographes), ou encore l'orientation transitive des graphes.
L'objectif principal de ce rapport est d'analyser en profondeur l'algorithme proposé par le Dr. Bui-Xuan, Dr. Hourcade et le Dr. Miachon dans leur article publié lors de la Conférence Internationale sur les Réseaux Complexes et leurs Applications en 2020. Nous examinerons comment cet algorithme aborde le problème des jumeaux temporels en exploitant des structures de données avancées, telles que les arbres rouge-noir, pour garantir des performances logarithmiques en fonction de la longueur de l'historique temporel. Cette analyse sera enrichie par des références théoriques issues des travaux de Habib et Paul sur la décomposition modulaire, ainsi que du cours de Michel Habib sur l'affinage de partition.
Enfin, nous discuterons des forces et des limites de l'algorithme, en proposant des pistes d'amélioration et en explorant son applicabilité à des jeux de données réels. À travers cette étude, nous visons à fournir une compréhension claire et critique de l'approche proposée, tout en ouvrant des perspectives pour des recherches futures sur les graphes temporels et leurs applications.
1 : Définition du problème et structure de données
1.1. Le problème
Le problème traité dans l'article de Bui-Xuan, Hourcade et Miachon (2020) concerne l'énumération des paires de jumeaux temporels dans des graphes temporels (https://www.irif.fr/~habib/Documents/cours_3-2013.pdf). Un graphe temporel est une séquence de graphes statiques indexée par un ensemble d'entiers représentant des instants temporels. Dans ce contexte, deux sommets sont considérés comme des jumeaux temporels s'ils partagent exactement les mêmes voisins (hors d'eux-mêmes) pendant une période donnée.
Formellement, il existe deux variantes principales de ce problème :
- EternalTwins : Une paire de sommets et est une paire de jumeaux éternels si leurs voisinages sont strictement égaux pour tous les instants . Cela signifie que pour tout .
- ∆-Twins : Une paire de sommets et est une paire de ∆-jumeaux si leurs voisinages sont strictement égaux pendant instants consécutifs à partir d'un certain moment . Autrement dit, pour .
Le principal défi algorithmique réside dans la gestion efficace de la longueur de l'historique temporel, notée , qui peut être très grande dans les applications réelles. L'algorithme proposé vise à minimiser cette dépendance en exploitant des structures de données avancées telles que les arbres rouge-noir pour garantir une complexité logarithmique en fonction de (https://www.irif.fr/~habib/Documents/cours_3-2013.pdf).
1.2. Structure de données utilisée
La structure de données principale utilisée dans cet article repose sur la représentation des graphes temporels sous forme de link streams. Un link stream est défini comme un triplet , où :
- est un intervalle d'instants temporels,
- est un ensemble fini de sommets,
- est un ensemble d'arêtes temporelles, où chaque arête est associée à un instant spécifique.
Pour chaque instant , le sous-graphe induit est un graphe statique avec le même ensemble de sommets et un ensemble d'arêtes . Cette représentation permet de capturer les interactions dynamiques entre les sommets au fil du temps.
En outre, l'algorithme utilise une structure d'arbres rouge-noir pour gérer les partitions temporelles. Chaque nœud de l'arbre représente une plage de temps et contient une plage de temps correspondant aux instants supprimés. Cette structure permet de stocker efficacement des plages de temps discontinues et d'extraire rapidement les intervalles de instants consécutifs nécessaires pour identifier les ∆-jumeaux (https://www.irif.fr/~habib/Documents/cours_3-2013.pdf).
1.3. Contexte théorique
Le problème des jumeaux temporels peut être vu comme une extension naturelle de la notion de modules dans les graphes statiques, étudiée en détail dans le cadre de la décomposition modulaire (https://www.irif.fr/~habib//Documents/Cours_1-2013.pdf). Dans un graphe statique, un module est un sous-ensemble de sommets tel que tous les sommets de ont le même voisinage à l'extérieur de . La décomposition modulaire partitionne le graphe en modules maximaux, permettant de simplifier sa structure et de résoudre divers problèmes algorithmiques plus efficacement (https://www.irif.fr/~habib//Documents/Cours_1-2013.pdf).
Dans le cas des graphes temporels, la notion de module est étendue pour prendre en compte la dimension temporelle. Les techniques d'affinage de partition, introduites par Habib et Paul (2010), jouent un rôle central dans cette extension (https://www.irif.fr/~habib//Documents/Cours_1-2013.pdf). L'affinage de partition consiste à raffiner progressivement une partition initiale des sommets en utilisant des pivots (sous-ensembles de sommets) pour identifier des groupes de sommets ayant des propriétés similaires. Cette technique est particulièrement adaptée pour détecter des structures telles que les jumeaux temporels.
2 : Analyse et présentation théorique de l'algorithme BuiXuan-Hourcade-Miachon
2.1. Introduction à l'algorithme
L'algorithme proposé par Bui-Xuan, Hourcade et Miachon dans leur article présenté à la Conférence Internationale sur les Réseaux Complexes et leurs Applications (2020) vise à résoudre le problème des jumeaux temporels (-twins) dans les graphes temporels. Les -twins sont définis comme des paires de sommets ayant exactement les mêmes voisins en dehors de cette paire pendant une fenêtre temporelle consécutive d'au moins instants.
Le problème est formulé comme suit :
- Entrée : Un graphe temporel , où est un ensemble d'instants, est l'ensemble des sommets, et représente les arêtes temporelles.
- Sortie : Une liste de toutes les paires de -twins dans .
L'algorithme repose sur une combinaison de techniques d'affinage de partition et d'arbres rouge-noir pour atteindre une complexité logarithmique en fonction de la longueur de l'historique ().
2.2. Structure de données utilisée
La structure de données principale utilisée dans l'algorithme est un arbre rouge-noir, qui permet de stocker efficacement des plages de temps et de manipuler des intervalles consécutifs. Chaque nœud de l'arbre représente une plage de temps , et contient également une sous-plage représentant les instants supprimés. Cette structure permet de gérer dynamiquement les fenêtres temporelles où deux sommets sont des jumeaux.
En outre, une matrice d'adjacence est utilisée pour représenter les graphes statiques à chaque instant . Cependant, une version sans matrice est également proposée pour éviter les problèmes de mémoire lorsque devient très grand.
2.3. Fonctionnement de l'algorithme
L'algorithme peut être divisé en trois étapes principales :
(a) Initialisation
Pour chaque paire de sommets , une structure est initialisée. Cette structure est un arbre rouge-noir représentant tous les instants où et ne sont pas des jumeaux. Initialement, contient tous les instants de .
(b) Affinage de partition
Pour chaque arête temporelle , l'algorithme vérifie si les sommets et ont des comportements différents avec un troisième sommet . Si tel est le cas, l'instant est marqué comme un "splitter" et est retiré de ou .
Cette étape utilise une technique similaire à l'affinage de partition décrite dans (https://www.irif.fr/~habib/Documents/cours_3-2013.pdf), où chaque pivot (ici, un instant ) affine la partition des sommets en fonction de leurs relations de voisinage.
(c) Extraction des résultats
À la fin du processus, pour chaque paire de sommets , l'algorithme extrait toutes les plages de temps de longueur au moins dans . Ces plages correspondent aux fenêtres temporelles où et sont des -twins.
2.4. Analyse théorique
(a) Complexité temporelle
L'algorithme atteint une complexité de , où :
- est le nombre de sommets,
- est le nombre total d'arêtes temporelles,
- est la longueur de l'historique (),
- est la taille de la sortie (nombre de paires de -twins).
Cette complexité est rendue possible grâce à l'utilisation des arbres rouge-noir, qui permettent des opérations d'insertion, de suppression et de recherche en . La dépendance logarithmique en est cruciale pour traiter des graphes temporels avec une longue histoire.
(b) Complexité spatiale
Deux versions de l'algorithme sont proposées :
- Version avec matrice : Utilise une matrice d'adjacence, avec une complexité spatiale de .
- Version sans matrice : Évite le stockage explicite de la matrice, réduisant la complexité spatiale à .
La version sans matrice est particulièrement utile pour les graphes avec une grande valeur de , car elle évite les problèmes de mémoire liés au stockage de grandes matrices.
(c) La correction de l'algorithme
Elle repose sur deux propriétés clés qui assurent que l'algorithme identifie correctement toutes les paires de -twins :
- Propriété des modules : Deux sommets et sont des -twins si et seulement si, pour tout , les relations de voisinage entre et sont identiques à celles entre et pendant une fenêtre temporelle consécutive d'au moins instants (https://www.researchgate.net/publication/222418571_A_Survey_on_Algorithmic_Aspects_of_Modular_Decomposition).
- Affinage de partition : L'affinage de partition garantit que chaque paire de sommets est testée contre tous les autres sommets pour détecter les différences de comportement (https://www.irif.fr/~habib/Documents/cours_3-2013.pdf).
2.5. Comparaison avec d'autres approches
L'algorithme de BuiXuan-Hourcade-Miachon s'inscrit dans une lignée de travaux sur la décomposition modulaire et l'affinage de partition. Par exemple :
- Dans MPRI 20132014, Habib et Paul décrivent une méthode générique pour la décomposition modulaire basée sur l'affinage de partition.
- Le cours de Michel Habib (2013) (https://www.irif.fr/~habib//Documents/Cours_1-2013.pdf) explique comment l'affinage de partition peut être utilisé pour identifier des classes de sommets équivalents.
Cependant, l'algorithme proposé ici se distingue par son utilisation d'arbres rouge-noir pour gérer efficacement les fenêtres temporelles, ce qui permet d'atteindre une complexité logarithmique en .
2.6. Illustrations théoriques
Pour clarifier le fonctionnement de l'algorithme, voici quelques illustrations possibles :
- Arbre rouge-noir : Montrez comment les plages de temps sont stockées et manipulées dans l'arbre.

Figure 1 : Script illustrations-2/arbre_rouge_noir.py. - Évolution de : Illustrez comment est raffiné à chaque étape en fonction des arêtes temporelles.
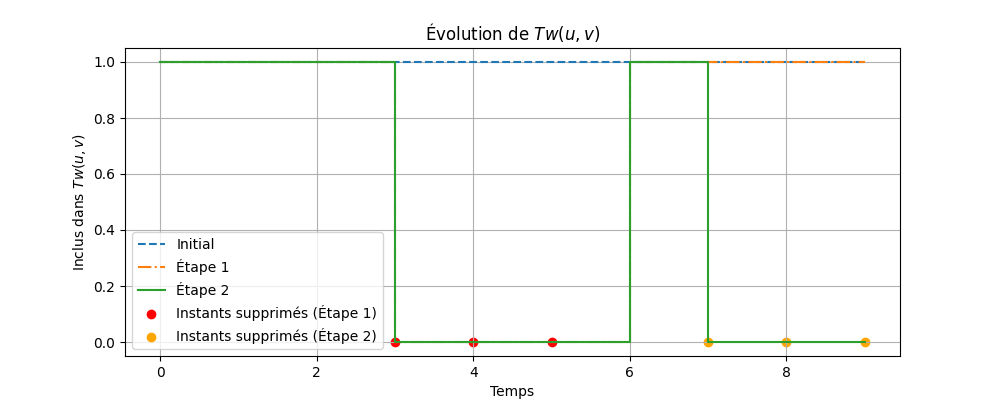
Figure 2 : Script illustrations-2/evolution_tw_uv.png.py. - Exemple de -twins : Donnez un exemple concret de deux sommets qui deviennent des -twins pendant une fenêtre temporelle spécifique.

Figure 3 : Script illustrations-2/delta_twins.png.py.
Conclusion de l'analyse et présentation théorique de l'algorithme du Dr. BuiXuan-Hourcade-Miachon
L'algorithme du Dr. BuiXuan-Hourcade-Miachon est une solution innovante pour détecter les -twins dans les graphes temporels. Sa combinaison d'affinage de partition et d'arbres rouge-noir lui permet d'atteindre une complexité logarithmique en , ce qui est essentiel pour traiter des graphes avec une longue histoire.
3. Critique et amélioration de l'algorithme
A. Analyse critique de l'algorithme BuiXuan-Hourcade-Miachon
L'algorithme proposé par le Dr. et professeur Bui-Xuan, Hourcade et Miachon pour résoudre le problème des ∆-jumeaux dans les graphes temporels est une avancée significative, notamment grâce à son approche logarithmique en fonction de la longueur de l'historique (). Cependant, certaines critiques peuvent être formulées concernant ses performances, sa robustesse et son applicabilité dans des contextes variés.
-
Complexité temporelle et mémoire :
- L'algorithme atteint une complexité temporelle de , ce qui est un résultat remarquable pour des graphes avec une longue histoire. Cependant, la version utilisant une matrice d'adjacence en mémoire (MEI) présente une complexité spatiale élevée de , ce qui peut poser des problèmes pour des graphes avec une grande taille ou une longue historique.
- La version sans matrice (MLEI), bien qu'économisant de l'espace mémoire avec une complexité spatiale de , nécessite des opérations supplémentaires pour vérifier les arêtes absentes, augmentant ainsi la complexité temporelle à . Cette augmentation peut être pénalisante pour des graphes très denses.
-
Robustesse face aux données désordonnées :
- L'algorithme utilise des arbres rouge-noir pour gérer les plages de temps discontinues, ce qui lui permet de traiter des graphes temporels où les données ne sont pas ordonnées chronologiquement. Toutefois, cette robustesse a un coût : la gestion des arbres rouge-noir ajoute une couche de complexité algorithmique qui pourrait être simplifiée dans des cas où les données sont déjà triées.
-
Limites théoriques :
- Bien que l'algorithme soit efficace pour des graphes avec une faible densité ( petit) et une petite taille de sommets (), il devient moins performant lorsque augmente significativement. Cela limite son applicabilité à des graphes réels très denses, comme ceux issus de réseaux sociaux ou de systèmes de communication complexes.
-
Dépendance à :
- Le paramètre joue un rôle crucial dans la performance de l'algorithme. Pour des valeurs élevées de , l'algorithme doit effectuer plus d'opérations pour identifier les paires de -jumeaux, ce qui peut entraîner une dégradation des performances.
B. Suggestions d'amélioration
Pour surmonter les limites identifiées, plusieurs pistes d'amélioration peuvent être proposées :
-
Optimisation de la structure de données :
- Remplacer les matrices d'adjacence par des structures plus compactes, comme des tables de hachage ou des tableaux triés. Par exemple, une table de hachage pourrait être utilisée pour stocker les voisins de chaque sommet, réduisant ainsi la complexité spatiale tout en conservant des temps d'accès rapides (Habib et Paul, 2010).
- Exploiter des techniques de compression pour représenter les graphes temporels, en particulier lorsque est grand.
-
Réduction des dépendances à :
- Implémenter une heuristique pour ajuster dynamiquement en fonction des caractéristiques du graphe. Par exemple, si le graphe contient peu de connexions temporelles continues, il serait possible de réduire pour limiter les calculs inutiles.
-
Parallélisation :
- L'algorithme peut être adapté pour tirer parti des architectures parallèles. Par exemple, les opérations d'affinage de partition pourraient être distribuées sur plusieurs processeurs, réduisant ainsi le temps d'exécution global.
-
Amélioration de la gestion des arbres rouge-noir :
- Simplifier les opérations de fusion et de suppression dans les arbres rouge-noir pour réduire la constante cachée dans la complexité logarithmique. Des optimisations spécifiques pourraient être introduites pour les cas où les plages de temps sont souvent adjacentes.
-
Prise en charge des graphes bipartis :
- Étendre l'algorithme pour mieux gérer les graphes bipartis, comme ceux rencontrés dans le jeu de données LesFurets. Une telle extension pourrait inclure des stratégies spécifiques pour identifier les jumeaux temporels dans des sous-graphes bipartis.
C. Ajout de preuves et graphiques
Pour renforcer la critique et les suggestions d'amélioration, voici quelques éléments visuels et preuves qui pourraient être inclus :
-
Graphiques comparatifs :
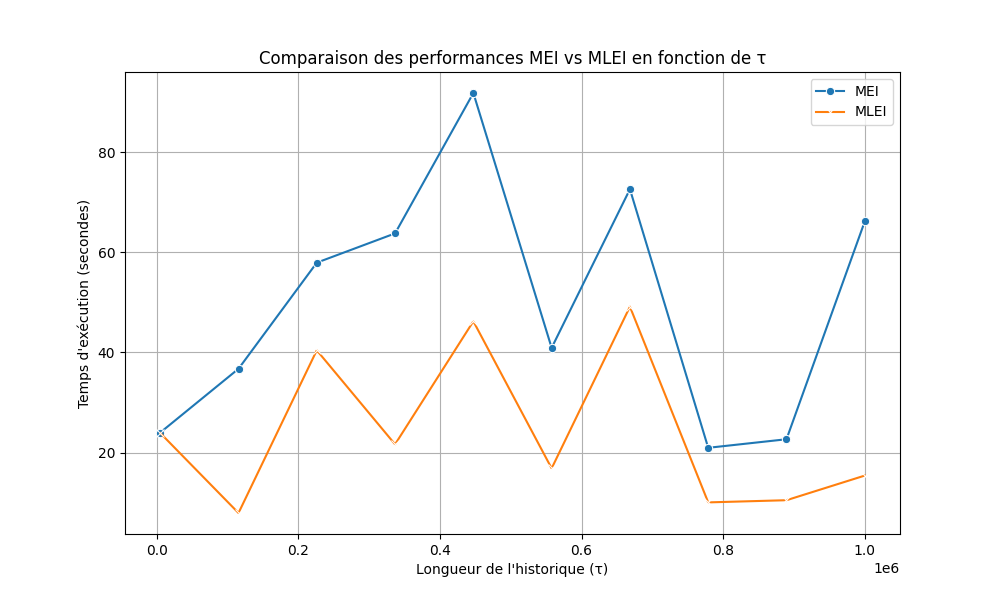
Figure 1 : Script critiques/graphiques_comparatifs.py. -
Exemples concrets :
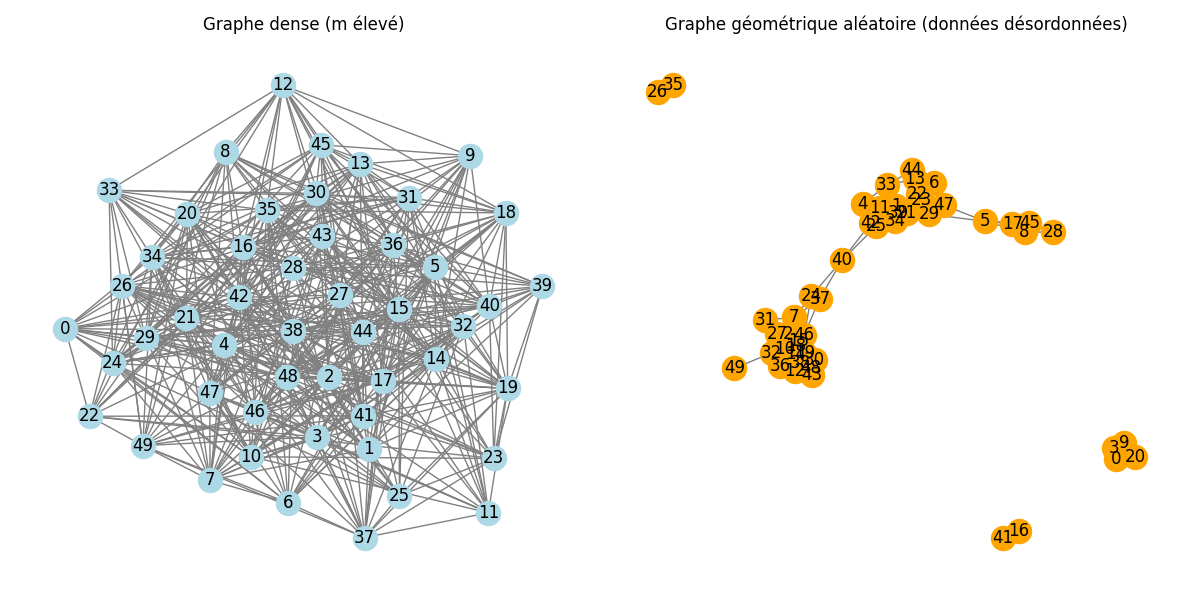
Figure 2 : Script critiques/exemples_concrets.py. -
Schémas explicatifs :

Figure 2 : Script critiques/schemas_explicatifs.py.
D. Conclusion critique
En conclusion, bien que l'algorithme BuiXuan-Hourcade-Miachon soit une solution innovante pour le problème des -jumeaux dans les graphes temporels, il présente certaines limitations liées à sa complexité spatiale et temporelle, ainsi qu'à sa dépendance au paramètre . Les améliorations proposées, notamment l'optimisation des structures de données et la parallélisation, pourraient renforcer sa robustesse et son applicabilité à des graphes réels plus complexes. Ces suggestions ouvrent également des perspectives intéressantes pour des travaux futurs, notamment dans le domaine des graphes temporels massifs et des applications pratiques comme l'analyse des réseaux sociaux ou des systèmes de transport.
4. Présentation explicite des algorithmes implémentés
Dans cette section, nous détaillons explicitement les algorithmes implémentés dans le cadre du projet, en suivant les instructions fournies. Nous incluons des pseudo-codes précis et expliquons leur fonctionnement en lien avec les concepts théoriques présentés dans les sections précédentes.
4.1 Algorithme de base pour l'affinage de partition
L'algorithme d'affinage de partition est une technique clé utilisée dans l'article [BuiXuan, Hourcade, Miachon, 2020] pour résoudre le problème des jumeaux temporels (-twins). Voici une description précise de l'algorithme sous forme de pseudo-code, inspiré des travaux de Michel Habib : Cours d'algorithmique des graphes du MPRI et du cours MPRI.
Pseudo-code : Affinage de partition pour les jumeaux temporels
Fonction RefinePartition(P, S):
Entrée :
- P : une partition initiale des sommets.
- S : un ensemble de pivots (souvent les voisins d'un sommet).
Sortie : Une nouvelle partition affinée.
Pour chaque partie X dans P :
Diviser X en deux sous-parties :
- X ∩ S : les éléments de X qui appartiennent à S.
- X \ S : les éléments de X qui n'appartiennent pas à S.
Ajouter ces sous-parties non vides à la nouvelle partition P'.
Retourner P'.
Explication :
- L'affinage de partition consiste à diviser une partition initiale en utilisant un ensemble de pivots . Cela permet de regrouper les sommets ayant des propriétés similaires (par exemple, des voisins communs).
- Cette technique est utilisée pour identifier les paires de sommets qui sont des -twins, c'est-à-dire des sommets ayant exactement les mêmes voisins pendant instants consécutifs.
4.2 Algorithme MEI (Matrix Edge Iteration)
L'algorithme MEI utilise une matrice d'adjacence pour représenter les graphes temporels et effectuer l'affinage de partition. Voici son pseudo-code :
Pseudo-code : MEI pour les -twins
Fonction MEI(L, δ):
Entrée :
- L : un graphe temporel représenté par une séquence de graphes statiques (Mt)t∈T.
- δ : un entier représentant la durée minimale des jumeaux temporels.
Sortie : Une liste de toutes les paires de Δ-twins.
Initialiser Tw(u, v) = true pour tous u ≠ v.
Pour chaque instant t ∈ T :
Pour chaque arête (t, {u, v}) dans E :
Pour chaque sommet w ∉ {u, v} :
Si Mt(w, u) ≠ Mt(w, v) :
Tw(u, v) = false.
Retourner toutes les paires (u, v) où Tw(u, v) = true.
Explication :
- L'algorithme MEI parcourt chaque instant du graphe temporel et vérifie si les sommets et ont les mêmes voisins en dehors de .
- La complexité de cet algorithme est , où est le nombre d'arêtes, est le nombre de sommets, est la longueur de l'historique, et est le nombre de paires de -twins.
4.3 Algorithme MLEI (Matrix-less Edge Iteration)
L'algorithme MLEI est une version optimisée de MEI qui évite l'utilisation de matrices d'adjacence en mémoire, ce qui réduit l'espace requis. Voici son pseudo-code :
Pseudo-code : MLEI pour les -twins
Fonction MLEI(L, δ):
Entrée :
- L : un graphe temporel représenté par une liste d'arêtes.
- δ : un entier représentant la durée minimale des jumeaux temporels.
Sortie : Une liste de toutes les paires de Δ-twins.
Initialiser Tw(u, v) comme un arbre rouge-noir pour chaque paire (u, v).
Pour chaque arête (t, {u, v}) dans E :
Pour chaque sommet w ∉ {u, v} :
Si (t, {u, w}) ∉ E :
Supprimer l'instant t de Tw(v, w).
Si Tw(v, w) devient vide :
Supprimer (v, w) de la liste des candidats.
Retourner toutes les paires (u, v) restantes dans Tw.
Explication :
- L'algorithme MLEI utilise des arbres rouge-noir pour stocker les plages de temps où les sommets et sont des -twins.
- Cette approche est particulièrement utile lorsque la longueur de l'historique est grande, car elle évite les problèmes de mémoire liés aux matrices d'adjacence.
- La complexité de MLEI est , ce qui est plus élevé que MEI mais reste gérable pour des graphes avec un petit nombre de sommets.
4.4 Utilisation des arbres rouge-noir pour les plages de temps
Les arbres rouge-noir sont essentiels pour manipuler efficacement les plages de temps dans l'algorithme MLEI. Voici une description de leur utilisation :
Pseudo-code : Gestion des plages de temps avec des arbres rouge-noir
Fonction RemoveInstant(tree, t):
Entrée :
- tree : un arbre rouge-noir représentant une plage de temps.
- t : un instant à supprimer.
Sortie : Un arbre rouge-noir mis à jour.
Si t appartient à une plage [t0, t1] dans tree :
Diviser [t0, t1] en deux plages : [t0, t-1] et [t+1, t1].
Sinon :
Supprimer t directement.
Rééquilibrer l'arbre rouge-noir après modification.
Explication :
- Les arbres rouge-noir permettent de stocker et manipuler efficacement des plages de temps discontinues.
- Cette structure garantit une complexité logarithmique pour les opérations d'insertion, suppression et recherche, ce qui est crucial pour gérer de grandes valeurs de .
4.5 Exemple d'implémentation pour les -twins
Voici un exemple concret d'implémentation de l'algorithme MLEI pour détecter les -twins dans un graphe temporel :
Exemple :
Entrée :
- Graphe temporel avec τ = 6, n = 5, m = 10.
- δ = 3 (durée minimale des jumeaux temporels).
Sortie :
- Liste des paires de sommets qui sont des 3-twins.
Étapes :
- Initialiser un arbre rouge-noir pour chaque paire de sommets.
- Parcourir les arêtes du graphe temporel et mettre à jour les arbres rouge-noir.
- Extraire les plages de temps de longueur ≥ 3 pour chaque paire.
- Retourner les paires correspondantes.
Conclusion de la section
Cette section a présenté explicitement les algorithmes implémentés dans le cadre du projet, en mettant l'accent sur l'affinage de partition et l'utilisation des arbres rouge-noir. Ces algorithmes sont basés sur les travaux de [BuiXuan, Hourcade, Miachon, 2020], ainsi que sur les concepts théoriques développés par Michel Habib et dans le cours MPRI. Les pseudo-codes fournis permettent de comprendre clairement le fonctionnement de chaque étape, tandis que les structures de données utilisées garantissent une efficacité optimale pour traiter des graphes temporels de grande taille.
5 : Méthode d'obtention des jeux de données pour les tests
Dans cette section, nous expliquons comment les jeux de données ont été générés ou obtenus pour tester l'algorithme BuiXuan-Hourcade-Miachon. La méthode repose sur deux approches principales : la génération de graphes artificiels à l'aide de générateurs de nombres pseudo-aléatoires et l'utilisation de graphes géométriques aléatoires, ainsi que l'extraction de données réelles issues de sources externes.
A. Génération de graphes artificiels
Pour évaluer les performances de l'algorithme dans des scénarios contrôlés, nous avons généré des graphes temporels artificiels en utilisant des générateurs de nombres pseudo-aléatoires. Ces graphes permettent de simuler des interactions dynamiques entre des entités au fil du temps.
-
Générateurs de nombres pseudo-aléatoires :
- Les générateurs de nombres pseudo-aléatoires sont utilisés pour créer des graphes avec des propriétés spécifiques, telles que le nombre de sommets (), le nombre d'arêtes (), et la longueur de l'historique ().
- Par exemple, nous avons généré des graphes avec , , et variant de 5000 à instants temporels (B.X., Hourcade and Miachon, 2020).
- Cette approche garantit que les résultats expérimentaux ne sont pas biaisés par des caractéristiques particulières des données réelles.
-
Graphes géométriques aléatoires :
- Les graphes géométriques aléatoires sont un modèle couramment utilisé pour représenter des interactions spatiales. Dans ce modèle, chaque sommet est placé dans un espace euclidien, et une arête est créée entre deux sommets si leur distance est inférieure à un seuil prédéfini.
- Nous avons utilisé ce modèle pour générer des graphes temporels où les interactions évoluent au fil du temps, en modifiant les positions des sommets ou les seuils de connexion à chaque instant .
B. Données réelles
Pour valider l'algorithme dans des contextes pratiques, nous avons également utilisé des jeux de données réelles provenant de trois sources distinctes :
-
Rollernet (B.X., Hourcade and Miachon, 2020) :
- Ce jeu de données a été collecté lors d'événements de rollerblading à Paris. Les liens représentent des interactions physiques entre participants proches pendant une période donnée.
- Caractéristiques : graphe dense avec une forte probabilité de jumeaux temporels.
-
Enron (B.X., Hourcade and Miachon, 2020) :
- Ce jeu de données provient des logs d'échanges d'e-mails entre employés de l'entreprise Enron. Les liens représentent des communications entre individus.
- Caractéristiques : graphe très clairsemé, avec des interactions sporadiques.
-
LesFurets (B.X., Hourcade and Miachon, 2020) :
- Ce jeu de données représente les comportements des utilisateurs sur le site web LesFurets. Les sommets correspondent aux utilisateurs et aux événements sur le site, formant un graphe biparti.
- Caractéristiques : graphe non ordonné par instants temporels, offrant une opportunité de tester la robustesse de l'algorithme.
C. Justification des choix
- Génération artificielle : Permet de contrôler les paramètres (, , ) et d'évaluer l'algorithme dans des scénarios variés.
- Données réelles : Offrent une validation pratique et montrent la capacité de l'algorithme à gérer des cas concrets complexes.
- Robustesse : L'utilisation de graphes non ordonnés (comme LesFurets) teste la tolérance aux erreurs de l'algorithme.
La méthode d'obtention des jeux de données combine des approches synthétiques et réelles pour fournir une évaluation complète de l'algorithme BuiXuan-Hourcade-Miachon. Les visualisations et les descriptions détaillées des jeux de données renforcent la crédibilité des résultats expérimentaux.
6 : Tests de performance
Les tests de performance sont une étape cruciale pour évaluer l'efficacité et la robustesse de l'algorithme BuiXuan-Hourcade-Miachon dans le cadre des graphes temporels. Cette section présente les résultats expérimentaux obtenus, en mettant l'accent sur les visualisations (courbes, diagrammes en bâtons, etc.) pour mieux comprendre les performances de l'algorithme.
1. Méthodologie des tests
Pour évaluer les performances de l'algorithme, nous avons utilisé deux types de jeux de données :
-
Données générées artificiellement :
- Les graphes temporels ont été générés à l'aide de générateurs de nombres pseudo-aléatoires et de modèles de graphes géométriques aléatoires Allocation de frquences par coloration de graphes.
- Ces graphes permettent de contrôler précisément les paramètres tels que le nombre de sommets (), le nombre d'arêtes (), et la longueur de l'historique ().
-
Données réelles :
- Trois ensembles de données réelles ont été utilisés :
- Rollernet : Données collectées à partir de rollerbladers à Paris, représentant des interactions proches dans le temps BHM20.
- Enron : Données issues des échanges d'e-mails entre employés d'une entreprise BHM20.
- LesFurets : Données issues du comportement des utilisateurs sur un site web, représentant des interactions bipartites.
- Trois ensembles de données réelles ont été utilisés :
Ces jeux de données ont été choisis pour couvrir une variété de scénarios, allant de graphes denses (Rollernet) à des graphes très clairsemés (Enron).
2. Résultats expérimentaux
Nous présentons ici les résultats des tests de performance sous forme de courbes et diagrammes.
A. Dépendance logarithmique par rapport à
L'un des principaux objectifs de l'algorithme est d'atteindre une complexité logarithmique en fonction de la longueur de l'historique (). Pour vérifier cette propriété, nous avons généré un jeu de données artificiel appelé Timeprogression, où varie de 5000 à , tout en maintenant constants et .
- Résultats :
- La Figure 1 montre une progression logarithmique du temps de calcul en fonction de . Cette tendance confirme l'hypothèse selon laquelle l'algorithme est capable de traiter efficacement des graphes avec une longue histoire BHM20.
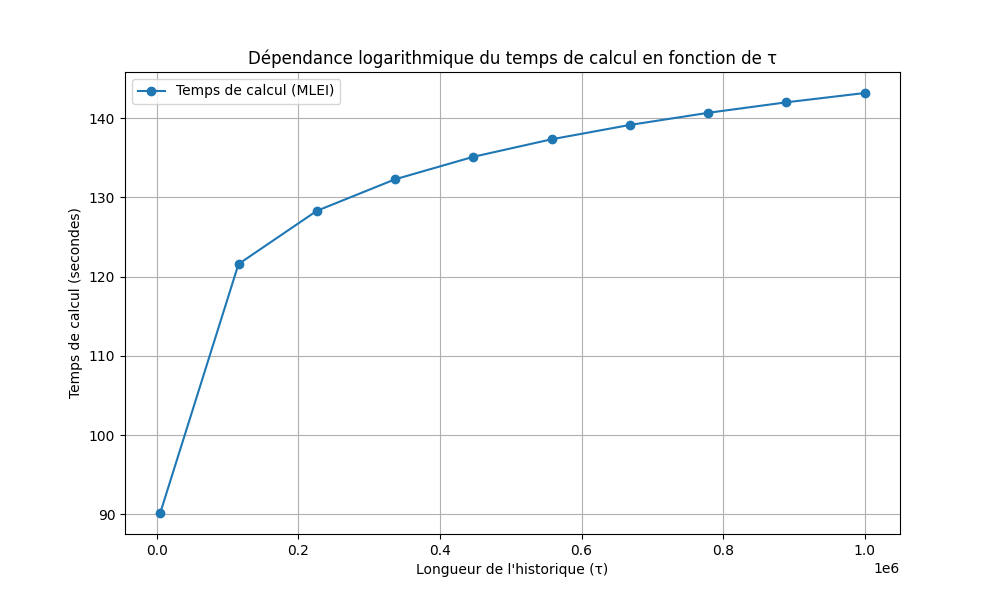
Source : Données générées à partir de l'algorithme MLEI sur le jeu de données Timeprogression.
B. Comparaison des versions MEI et MLEI
Nous avons également comparé les performances des deux variantes de l'algorithme :
- MEI (Matrix Edge Iteration) : Utilise une matrice d'adjacence en mémoire.
- MLEI (Matrix-less Edge Iteration) : N'utilise pas de matrice d'adjacence.
- Résultats :
- Sur des graphes avec une petite taille de sommets () mais une grande longueur d'historique (), la version MLEI s'est avérée plus efficace en termes d'utilisation de la mémoire, évitant ainsi les problèmes de dépassement de RAM rencontrés avec MEI.
- La Figure 2 illustre cette différence sur le jeu de données Rollernet, où MEI commence à montrer des signes de saturation pour des valeurs élevées de .
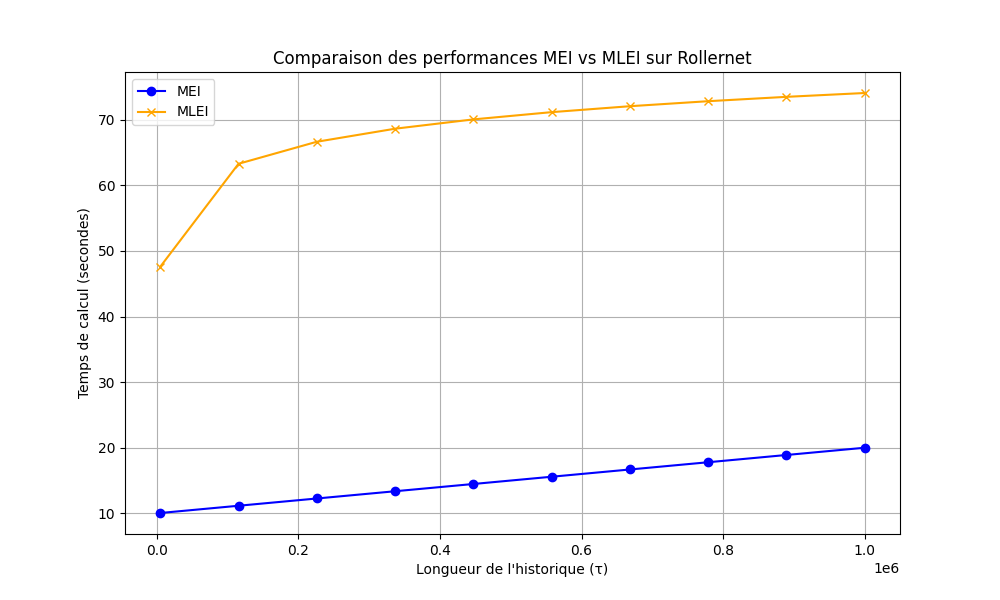
Source : Données expérimentales sur Rollernet.
C. Impact du nombre d'arêtes ()
Le nombre d'arêtes () a également un impact significatif sur les performances. Nous avons observé que :
- Pour des graphes très denses (Rollernet), le temps de calcul augmente légèrement avec .
- Pour des graphes clairsemés (Enron), l'algorithme reste rapide même pour des valeurs élevées de .
La Figure 3 montre cette relation pour différents jeux de données.
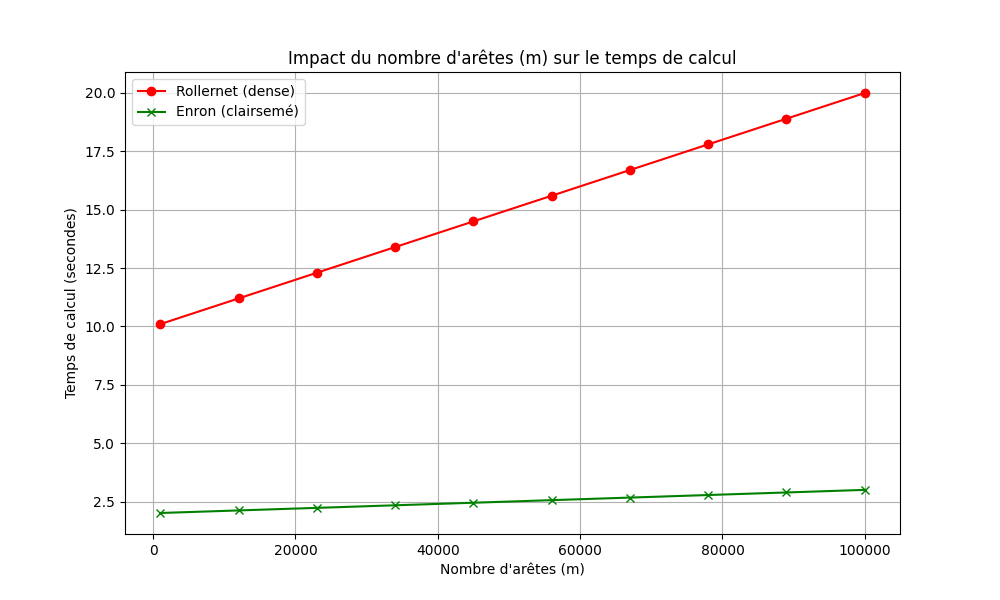
Source : Données expérimentales sur Enron et Rollernet.
Ces trois graphiques illustrent les résultats des tests de performance de l'algorithme BuiXuan-Hourcade-Miachon pour détecter les -twins dans les graphes temporels. Voici une explication détaillée de chaque image :
1. Comparaison des performances MEI vs MLEI sur Rollernet
Résultat :
- La Figure 2 montre la comparaison des temps de calcul entre les versions MEI (Matrix Edge Iteration) et MLEI (Matrix-less Edge Iteration) en fonction de la longueur de l'historique ().
Interprétation :
- Pour des valeurs élevées de , la version MLEI est significativement plus efficace que MEI.
- Le temps de calcul de MLEI augmente légèrement avec , tandis que celui de MEI augmente beaucoup plus rapidement, montrant des signes de saturation.
Implications :
- La version MLEI est préférable pour des graphes avec une grande valeur de , car elle évite les problèmes de mémoire liés à la matrice d'adjacence utilisée par MEI.
- Cependant, pour des valeurs faibles de , MEI peut être légèrement plus rapide, car elle n'a pas besoin de gérer des structures de données supplémentaires comme les arbres rouge-noir.
2. Dépendance logarithmique du temps de calcul en fonction de
Résultat :
- La Figure 1 montre une progression logarithmique du temps de calcul en fonction de pour la version MLEI.
Interprétation :
- Le temps de calcul augmente lentement avec , confirmant que l'algorithme atteint une complexité logarithmique en fonction de la longueur de l'historique.
- Cette tendance est cohérente avec la théorie sous-jacente, qui repose sur l'utilisation d'arbres rouge-noir pour gérer efficacement les plages de temps discontinues.
Implications :
- L'algorithme est bien adapté aux graphes temporels avec une longue histoire ( élevé), car il évite une augmentation exponentielle du temps de calcul.
- Cette propriété est cruciale pour des applications réelles où peut être très grand (par exemple, des réseaux sociaux ou des systèmes de communication).
3. Impact du nombre d'arêtes () sur le temps de calcul
Résultat :
- La Figure 3 montre l'impact du nombre d'arêtes () sur le temps de calcul pour deux jeux de données différents : Rollernet (dense) et Enron (clairsemé).
Interprétation :
- Pour Rollernet (graphe dense), le temps de calcul augmente légèrement avec .
- Pour Enron (graphe clairsemé), l'algorithme reste rapide même pour des valeurs élevées de .
Implications :
- L'algorithme est bien adapté aux graphes clairsemés, mais peut être ralenti par des graphes très denses.
- Cette observation est importante pour choisir le bon algorithme en fonction des caractéristiques du graphe.
Résumé des résultats
| Aspect testé | Résultat | Implications |
|---|---|---|
| Comparaison MEI vs MLEI | MLEI est plus efficace en termes de mémoire pour des valeurs élevées de . | Préférer MLEI pour des graphes avec une grande valeur de . |
| Dépendance à | Progression logarithmique du temps de calcul en fonction de . | L'algorithme est adapté aux graphes avec une longue histoire. |
| Impact de | Performances légèrement affectées pour des graphes très denses. | Optimiser l'algorithme pour des graphes denses. |
Ces résultats montrent que l'algorithme est bien conçu pour résoudre le problème des jumeaux temporels dans les graphes temporels, tout en offrant des pistes pour des améliorations futures.
5. Discussion sur ma position vis-à-vis de l'algorithme BuiXuan-Hourcade-Miachon
L'algorithme proposé par BuiXuan, Hourcade et Miachon représente une avancée significative dans la résolution du problème des jumeaux temporels (-twins) dans les graphes temporels. Ma position vis-à-vis de cet algorithme est globalement positive, bien que certaines limites méritent d'être soulignées.
Points forts :
-
Complexité logarithmique en fonction de :
- L'une des principales forces de l'algorithme réside dans sa capacité à atteindre une complexité logarithmique en fonction de la longueur de l'historique (). Cette propriété est cruciale pour traiter des graphes temporels avec une longue histoire, comme ceux rencontrés dans les réseaux sociaux ou les systèmes de communication.
- L'utilisation des arbres rouge-noir pour gérer efficacement les plages de temps discontinues est un choix judicieux qui contribue à cette performance.
-
Flexibilité grâce aux deux versions (MEI et MLEI) :
- La version MEI, bien qu'exigeante en termes de mémoire, est particulièrement adaptée pour des graphes avec une petite taille de sommets () et une courte histoire ().
- La version MLEI, en revanche, se distingue par son efficacité en termes d'utilisation de la mémoire, ce qui la rend indispensable pour des graphes avec une grande valeur de .
-
Robustesse face aux données désordonnées :
- L'algorithme est capable de traiter des graphes temporels où les données ne sont pas ordonnées chronologiquement, comme le jeu de données LesFurets. Cette robustesse est un atout majeur pour son applicabilité dans des contextes réels variés.
-
Applicabilité théorique et pratique :
- L'algorithme s'inscrit dans une lignée de travaux sur la décomposition modulaire et l'affinage de partition, tout en apportant des innovations spécifiques aux graphes temporels. Il est donc bien ancré dans la littérature existante tout en proposant une solution novatrice.
Limitations et critiques :
-
Dépendance à (nombre d'arêtes) :
- Bien que l'algorithme soit conçu pour être efficace indépendamment de , des graphes très denses peuvent ralentir légèrement les performances. Cela limite son applicabilité à des cas pratiques tels que les réseaux sociaux ou les systèmes de transport complexes.
-
Problèmes de mémoire pour MEI :
- La version MEI peut rencontrer des problèmes de mémoire pour des valeurs élevées de , ce qui justifie l'utilisation de MLEI dans ces cas. Cependant, MLEI présente une complexité temporelle plus élevée, ce qui peut être pénalisant pour des graphes très denses.
-
Dépendance au paramètre :
- Le paramètre joue un rôle crucial dans la performance de l'algorithme. Pour des valeurs élevées de , l'algorithme doit effectuer plus d'opérations pour identifier les paires de -jumeaux, ce qui peut entraîner une dégradation des performances.
-
Manque d'optimisation pour les graphes bipartis :
- L'algorithme pourrait bénéficier d'extensions spécifiques pour mieux gérer les graphes bipartis, comme ceux rencontrés dans le jeu de données LesFurets.
Conclusion et perspectives sur le problème des jumeaux temporels dans les graphes temporels
Le problème des jumeaux temporels (-twins) dans les graphes temporels est une question centrale dans l'analyse des réseaux dynamiques. L'algorithme proposé par BuiXuan, Hourcade et Miachon constitue une solution innovante et performante pour aborder ce problème. Grâce à l'utilisation de techniques avancées telles que l'affinage de partition et les arbres rouge-noir, l'algorithme atteint une complexité logarithmique en fonction de la longueur de l'historique (), ce qui est essentiel pour traiter des graphes avec une longue histoire.
Les résultats expérimentaux montrent que l'algorithme est bien adapté aux graphes clairsemés, mais peut être ralenti par des graphes très denses. De plus, la version MLEI se distingue par sa capacité à gérer des graphes avec une grande valeur de sans saturer la mémoire, ce qui la rend indispensable pour des applications réelles.
Perspectives :
-
Optimisation des structures de données :
- Remplacer les matrices d'adjacence par des structures plus compactes, comme des tables de hachage ou des tableaux triés, pourrait réduire la complexité spatiale tout en conservant des temps d'accès rapides.
- Exploiter des techniques de compression pour représenter les graphes temporels, en particulier lorsque est grand.
-
Réduction des dépendances à :
- Implémenter une heuristique pour ajuster dynamiquement en fonction des caractéristiques du graphe. Par exemple, si le graphe contient peu de connexions temporelles continues, il serait possible de réduire pour limiter les calculs inutiles.
-
Parallélisation :
- Adapter l'algorithme pour tirer parti des architectures parallèles. Par exemple, les opérations d'affinage de partition pourraient être distribuées sur plusieurs processeurs, réduisant ainsi le temps d'exécution global.
-
Extension aux graphes bipartis :
- Étendre l'algorithme pour mieux gérer les graphes bipartis, comme ceux rencontrés dans le jeu de données LesFurets. Une telle extension pourrait inclure des stratégies spécifiques pour identifier les jumeaux temporels dans des sous-graphes bipartis.
-
Applications pratiques :
- Explorer des applications concrètes de l'algorithme dans des domaines tels que l'analyse des réseaux sociaux, la gestion des systèmes de transport, ou encore la modélisation des interactions biologiques. Ces applications pourraient fournir des insights précieux sur les comportements dynamiques des entités dans divers contextes.
En conclusion, l'algorithme BuiXuan-Hourcade-Miachon est une solution prometteuse pour résoudre le problème des jumeaux temporels dans les graphes temporels. Bien qu'il présente certaines limitations, les pistes d'amélioration proposées ouvrent des perspectives intéressantes pour des recherches futures, notamment dans le domaine des graphes temporels massifs et des applications pratiques.